OSS Data Lakehouse - SQL and BI using Trino and Apache Superset
Add SQL query processing and BI dashboarding to a Data Lakehouse using OSS


What we'll be exploring in this post is an extension of the basic lakehouse setup that was created in the first post of the series. Please make sure you have it set up before continuing. And as before we will aim for maximum simplicity (e.g. putting everything into a single namespace, default configs) so this as-is shouldn't be used for real-world production systems.
In the first part we've managed to create our basic lakehouse on a Kubernetes cluster. But the ways to interact with the data in the current system are limited and kinda quirky - it's basically just Spark that requires building a Docker image and execution via a k8s manifest file. Additionally it doesn't really work that well for small queries as there is a certain overhead to creating the Spark cluster and cleaning it up afterwards. This works for bigger applications where that is handled by the CI and developed by DEs that specialize in Spark but is a sub-standard solution for e.g. data scientists or business analysts that want to quickly explore and play around with the data without the hassle and mainly use SQL.
So we would want to add two things:
- An easily accessible (and fast!) query engine that uses SQL to manipulate the data.
- A way to visualize the data, preferably with full dashboard-creation capabilities.
Fortunately open source has great answers two both of those points in the form of Trino and Apache Superset which we'll be using to implement the above functionality.
Trino
NOTE: My original preference here would be using StarRocks as it is a more performant and modern solution but unfortunately it doesn't (yet?) support Nessie as an Iceberg catalog.
In short Trino is a distributed, interactive SQL query engine that will let us execute queries against our data with high speed, thanks to it using a distributed worker model as Spark does. It is a well-established project and there exist many connectors to it so it also serves as a great expansion point for our system as we'll show later with Superset.
Adding it to our cluster is simple using Helm charts, we'll just need to do a bit of configuration to add our catalog info. Let's create a configuration file trino.yaml as follows:
additionalCatalogs:
standardized: |-
connector.name=iceberg
iceberg.catalog.type=nessie
iceberg.nessie-catalog.uri=http://nessie.lakehouse.svc.cluster.local:19120/api/v1/
iceberg.nessie-catalog.default-warehouse-dir=s3a://standardized/
iceberg.file-format=PARQUET
hive.s3.path-style-access=true
hive.s3.ssl.enabled=false
hive.s3.aws-access-key=lakehouse
hive.s3.aws-secret-key=lakehouse
hive.s3.endpoint=http://minio.lakehouse.svc.cluster.local
app: |-
connector.name=iceberg
iceberg.catalog.type=nessie
iceberg.nessie-catalog.uri=http://nessie.lakehouse.svc.cluster.local:19120/api/v1/
iceberg.nessie-catalog.default-warehouse-dir=s3a://app/
iceberg.file-format=PARQUET
hive.s3.path-style-access=true
hive.s3.ssl.enabled=false
hive.s3.aws-access-key=lakehouse
hive.s3.aws-secret-key=lakehouse
hive.s3.endpoint=http://minio.lakehouse.svc.cluster.localIt adds the two Iceberg catalogs (standardized and app) along with the details required for connecting with our data catalog (Nessie) and storage (MinIO).
Then we just add the Trino repository and install it to our namespace:
helm repo add trino https://trinodb.github.io/charts
helm repo update
helm install -f trino.yaml trino trino/trino --namespace=lakehouseAfter that is finished and the pods (driver + default amount of workers) are running we'll forward the Trino port to the outside so we can test it out:
kubectl --namespace lakehouse port-forward svc/trino 8080:8080We'll use the Trino CLI client to interact with it, downloading and running it can be done via:
wget https://repo1.maven.org/maven2/io/trino/trino-cli/444/trino-cli-444-executable.jar -O trino
chmod +x trino
./trino --server http://localhost:8080After that we should be in the Trino shell and can start running queries against our catalogs and tables.
In the Spark example we've wrote directly to the catalog without any schema but that is not really something we should do as the data will become disorganized pretty quickly and chaos will ensue. So we'll want to first create a schema to group the tables. After that in the newly created schema we'll create a test table with some example data that will be used later on for visuals. This can be done with the following SQL:
CREATE SCHEMA standardized.company_info;
CREATE TABLE standardized.company_info.accounts (id bigint, country_cd varchar(2), assets bigint);
INSERT INTO standardized.company_info.accounts VALUES (1, 'pl', 100), (2, 'de', 200), (3, 'pl', 50), (4, 'uk', 190), (5, 'uk', 20), (6, 'pl', 400), (7, 'de', 70);So we now have an easy way to execute SQL queries which additionally works extremely fast thanks to the distributed compute model and we've tested it works by adding some test data for the next part of the guide.
NOTE: It is usually a bad idea to create and add data via Trino in an ad-hoc manner. Usually we want logic that ingests and transforms data with persistence to be reviewed and unit tested. Also Trino isn't as fault-tolerant as Spark so for big jobs it is a major downside. It should be used mainly read-only.
Superset
Having a large amount of data and a way to process it with speed is great but what many end-users want is some efficient way of aggregating all that information into easy to digest visuals and knowledge, the process loosely known as "business intelligence" (BI).
The modern way of doing this is mainly via BI packages like Power BI, Tableau, Metabase, etc. that let us create interactive dashboards with visuals and graphs that can be then passed on to non-technical users like management for usage and feedback.
There's a few choices when it comes to open source BI packages but for our purposes we will choose Apache Superset as it offers an easy way to install (Helm chart), is being actively developed, it's fully open source and offers a great set of features (including Trino integration).
We can install it via Helm but first we'll need a resource file to override the secret or else the database init job won't work:
configOverrides:
secret: |
SECRET_KEY = 'apoBalnUrH0PBx8+V5diaBFt7M0mKSGrcEW0ojvCqW0sQoAZ9ZdmQAtC'Where the value of SECRET_KEY can be generated e.g. via openssl rand -base64 42
When that is prepared we can run:
helm repo add superset https://apache.github.io/superset
helm repo update
helm upgrade --install --values superset.yaml superset superset/superset --namespace=lakehouseIt might take a while for it to fully come up after installation but after it's up we can forward the port:
kubectl port-forward service/superset 8088:8088 --namespace lakehouseAnd then we can go to localhost:8088 with our browser and log in using the default admin/admin credentials. After which we'll see the main view:
To access the data via Trino we'll first need to install the required Python driver. The fastest (altough hacky) way of doing it is simply executing the pip install trino in the pods directly:
kubectl get pods --namespace lakehouse -l "release=superset" --no-headers -o custom-columns=":metadata.name" | xargs -I{} kubectl exec -it --namespace=lakehouse {} -- bash -c "pip install trino"The above will get the superset pod names (driver and worker) and execute the install of the trino package via pip.
Then we'll do the following:
- Go to Settings->Database Connection in the upper-right corner
- Click the + DATABASE button
- Choose Trino from the Choose a database dropdown
Then we'll get the form to fill out the connection details. These should be filled out as follows (the display name can be whatever you wish):
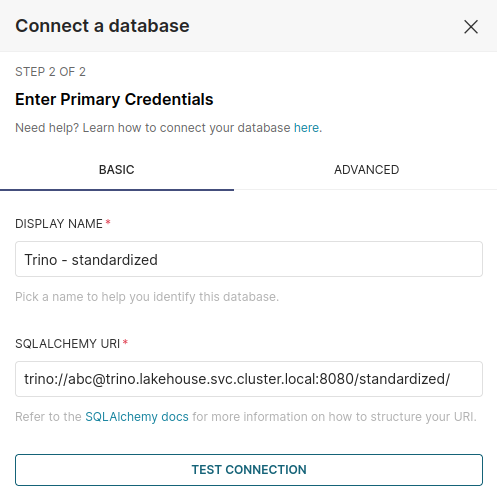
The abc username is not used for authentication as we don't have that set up but is still required for a correct connection URI.
NOTE: We can ommit the catalog name in the URI, that will enable us to use whatever catalog in the SQL queries but schema discovery won't work in the dataset creator as we'll only see auxiliary schemas of Nessie.
We finalize the creation of the connection by clicking the CONNECT button in the lower-right.
Now that we have a way of connecting with Trino and extracting the data we can proceed to the creation of a dataset using our company_info.accounts table. The required steps are as follows:
- Go to the Datasets tab
- Click the + DATASET
- Select the correct database (connection), schema (might need to hit the refresh button on the right) and table
- Click CREATE DATASET AND CREATE CHART in the lower right
An example of how it looks like filled out:

We will now see the page where we choose the type of chart to be created. We'll go with a pie chart. After choosing it click CREATE NEW CHART. In this new view we can configure what data will be used for the chart, how it will be transformed and the details of the looks. I've created a simple representation of the sum of the assets per country as follow, but it can be whatever you want:
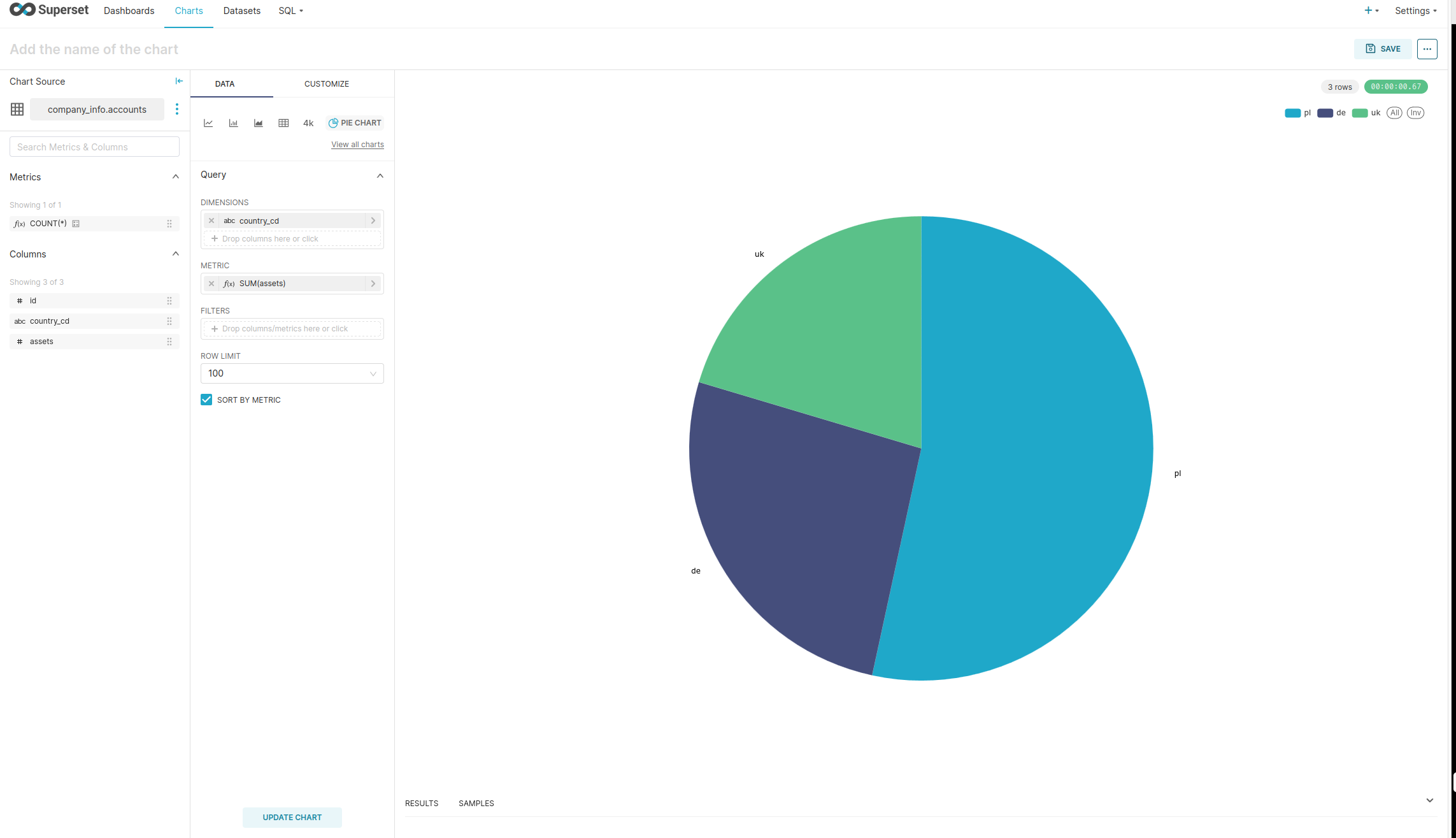
We can proceed to creating a dashboard and adding our chart to it but the details of doing that (and much more regarding the features and usage of Superset) can be found in the documenation so we'll end our journey here.
So we've achieved what we wanted - the data from the lakehouse was used via Trino by Superset to create a chart that neatly visualizes and presents the information stored in a table. Great stuff!
Conclusion
In this continuation of the previous guide we've managed to expand our little lakehouse with the following:
- Performant, interactive SQL queries via Trino
- Data visualization and BI via Superset
The above really brings a lot of usability to our little system and enables non-technical users to operate and interact with the data in a pretty straightforward way. Of course as previously we mainly use sub-optimal default configurations and cluster layout to make things easier, if you're planning on using Trino or Superset in a real-world setting please investigate the documenation and configure them properly. This is at most a baseline.
Most probably I will follow-up with a third part but I still need to iron-out what I would want to put there - Grafana monitoring (both system and lakehouse) and alerting seems like a good goal but we'll see when we get there.
Thank you for reading and as previously - I hope you've found helpful what was written here.
Cheers!